A while ago, I started a series of posts on finding new ways to fund public goods. Crowd-funding platforms, which have been enormously successful in 2012, promise a new way of financing creative projects and many of them employ the Street Performer Protocol, which was originally invented with a view towards financing public goods such as open source software projects. However, a closer look at the way the Street Performer Protocol is used on Kickstarter reveals that it is rarely employed to finance goods published under a copyleft license. Rather pledges are treated as pre-orders for goods sold as if they were classic private goods. I think we can do better than that!
In this post, I want to describe a different way to fund the private provision of public goods: the Average Cost Threshold Protocol.
Before we get started, let me clarify what I mean by the term public good. The term does not have the egalitarian meaning of a common good that is shared by everyone and that all members of a community are entitled to. Rather, a public good is any good that has a specific economic property: If a public good is provided to one person, it could also be provided to everybody else at no additional cost. Note that I am not saying the public good actually is provided to everyone. It may very well be that some people are excluded from using the public good. Also, I am not saying that nobody has to pay anything for the public good.
Practically all digital goods are natural public goods. This includes movies, music, ebooks, online lectures, scientific articles, software and computer games. These can, in principle, be copied at virtually no cost. Often, legal or technical restrictions are placed on copying these goods, as producers want to raise money for the provision of these goods by selling these goods as private goods (or by selling advertising tied to these goods). This post is about finding better ways to fund the creation of such digital goods. As my running example of a public good, I am going to use a computer game. Not because games are the most important type of public good, but simply because they are widely popular, require no maintenance after their release (or after, say, the tenth patch) and because a number of computer games have been very successful on Kickstarter, which shows that the audience is open to experimenting with new funding mechanisms.
The Theory of Average Cost Pricing of Public Goods
A very natural variation of threshold pledge systems like the Street Performer Protocol is a fixed fee mechanism with average cost prices. In this section I will present the theory behind this mechanism, before turning to its practical implementation (and a practical example!) in the next section.
The basic idea is very straightforward:
- Everybody interested in a given project makes a pledge, saying they are willing to contribute a certain amount of money to funding the project. If somebody is not interested in contributing that just don’t pledge anything.
- After all pledges have been made, we distribute the costs of the project equally among as many people as possible: Everybody pays exactly the average cost of the project, as long as they pledged at least as much. More precisely, we figure out the smallest price $p$ such that if everybody who pledged at least $p$ pays exactly the price $p$, then the costs of the project are covered exactly. Nobody pays more than $p$ and if somebody pledged less than $p$ they don’t have to pay anything.
- If there is no such price $p$, for example because people pledged too little, then the project is not funded and nobody pays anything!
- In case the project is funded, the money raised is used to create the public good. But only those people who paid get access to the public good! (Here we assume that the public good in question is excludable.)
Points 1 and 3 are very similar to the Street Performer Protocol (SPP) and what happens on Kickstarter. Point 2 is crucially different, as in the SPP and on Kickstarter everybody pays what they pledged and not the price $p$. Point 4 is what happens in many projects on Kickstarter, as I observed in my last post, but it is very different from the idea behind the SPP, which was intended to fund pure public goods without use exclusions. There is another vital difference to what happens on Kickstarter that will become clear in the next section.
The fixed fee mechanism with average cost prices has crucial theoretic advantages:
- Everybody has an incentive to pledge exactly what the project is actually worth to them. The technical term for this incentive compatibility. Note that the SPP is not incentive compatible: there, people have an incentive to understate the value the project has for them, in order to pay less. (This is called “free riding” in the public goods literature.)
- Nobody is forced to contribute anything if they don’t want to. In other words, no matter what happens, after we have used this mechanism, everybody will be at least as well-off as before. This is called individual rationality. Many mechanisms for funding public goods, both practical ones, such as taxation by the government, and theoretical ones, such as the Groves-Clarke mechanism, are not individually rational. But for the private provision of public goods in which people participate voluntarily, individual rationality is essential.
- If the fundraising is successful, we raise exactly as much money as is needed to fund the project. That is, the mechanism not only covers costs but moreover it balances the budget.
Of course this mechanism also has a key disadvantage: We exclude people form using the public good even though the public good could be provided to them at no extra cost. In technical terms we say the mechanism is inefficient. This, however, is unavoidable as there are theoretical results such as the Myerson-Satterthwaite Theorem which says, roughly, that there does not exist a mechanism for the provision of public goods that is incentive compatible, individually rational and efficient. This result tells us that the first best solution of giving everybody access to the public is impossible to attain. The good news is, though, that in face this impossibility result, the fixed fee mechanism with average cost prices is the best possible alternative:
- According to a result by Peter Norman the above mechanism is (asymptotically, in a large economy) the most efficient one among all mechanisms that are incentive compatible, individually rational and guarantee budget balance.
- If the cost of funding the public good is small in comparison to the total size of the economy and the number of people interested in the public good, then the average cost will approach zero. This allows us to get arbitrarily close to giving everyone access to the public good. See also this paper by Martin Hellwig.
Regarding the history of the fixed fee mechanism with average cost prices, I want to mention that average cost prices have been studied for a very long time in the context of monopoly economics and a number of authors have examined fixed fee mechanisms in the context of public goods. However, as far as I was able to find out, the paper by Peter Norman is the first instance where this exact mechanism has been studied in a public good setting.
Of course there is a lot more to say about these results and I plan to write more about the technical details in the future. But today, I want to talk about how this mechanism could work in practice and present a practical implementation which I dub the Average Cost Threshold Protocol.
The Average Cost Threshold Protocol in Practice
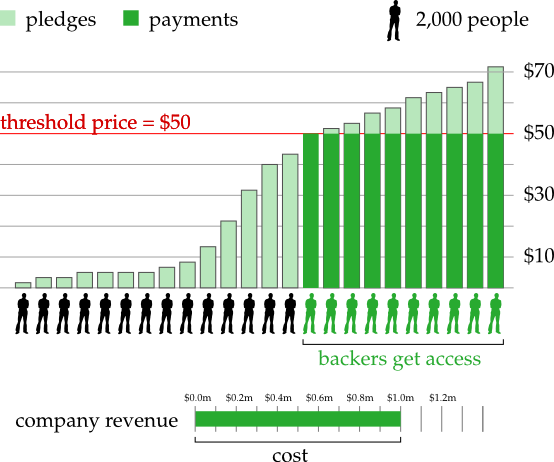
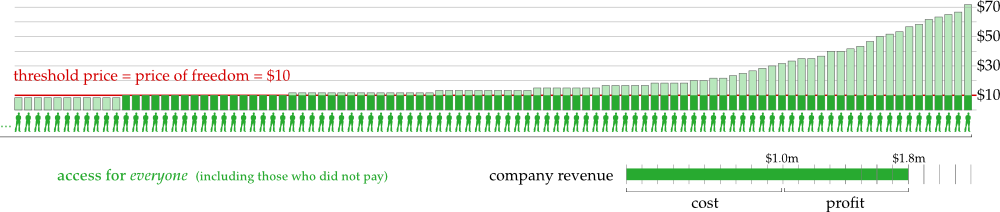
Suppose a company wants to create a computer game and they need money to cover their costs, which total, say, $1 million. They decide to use the above mechanism to raise the funds and so they start a project on a website like Kickstarter which provides all the necessary infrastructure. The project is open to receive pledges for 30 days and at the end of that period the pledges are tallied to see if the project can be funded according to the above rule. (Strictly speaking, setting a deadline is not necessary, but given that many crowd-funding projects raise a large part of their funds the days immediately before the deadline, it seems like a good idea to make use of this psychological effect.)
Many people chip in and pledge various amounts. There are 20,000 people who pledge \$50 or more. So setting a price of \$50 would exactly cover the costs of the game. However, there are only 23,000 people who pledge \$40 or more, so setting a price of \$40 would raise only \$0.92 million which does not cover the costs of the game. Let us assume that \$50 is the lowest price that covers the costs of the game.
Thus, the price is fixed at \$50 dollars. Everybody who pledged \$50 or more now has to pay exactly \$50 dollars. The people who pay these \$50 are now called backers. The total amount raised is \$1 million which covers the costs of the game. This money is used to create the game, and once it is finished, every backer receives a copy.
So far so good. But what about all the other people who would like to play the game? In all likelihood, there are many more people out there who would be happy to pay \$50 to get a copy! Maybe they heard about the project only after the fundraising ended, so they did not have a chance to become a backer. Or maybe they wanted to wait and see how the game turned out before committing to the purchase. Or maybe they did not have \$50 to spare back then, but they do now. Whatever their reasons, it makes perfect sense to provide these people with the public good - we just have to find a way that is consistent with our mechanism.
How do games companies currently do it on Kickstarter? Well, they just sell copies of the game. And the companies keep the revenues from these sales for their own profit. There is nothing wrong with creators making a profit from their work. The problem here is that this breaks our mechanism! Suppose there are another 20,000 people (let’s call them buyers as opposed to backers) who pay \$50 for the game and these revenues are the profits of the company. Now there are a total of 40,000 people (buyers + backers) who have paid \$50 each, which amounts to a total of \$2 million dollars. However distributing the total cost of the game (\$1 million) among 40,000 people would lead to an average cost of just \$25! So, in this scenario, if the company decides to sell the game for profit after it is finished, people would pay twice the average cost, which is very different from what our mechanism specifies.
So let’s suppose we take our mechanism seriously. What would need to happen with the profits from selling the game? Suppose we have 20,000 backers plus 20,000 buyers. As we observed above, distributing the costs of \$1 million equally among those 40,000 people would lead to an average cost of just \$25. But the backers already paid \$50! So here is what needs to happen according to the mechanism: The buyers need to pay just \$25 each. And these revenues need to be given to the backers instead of the company. This makes sure that everybody pays exactly the average cost of the public good.
But now the price of the good has dropped by 50% and the product is gaining ever more public attention. So now there are, say, 40,000 additional people out there who would be willing to pay \$25 for the game. Here is what the mechanism tells us to do: Charge each of the 40,000 newcomers \$12.50 and give the proceeds to the 40,000 people who purchased the game first. This way, everybody just paid \$12.50.
You can now see where this is going:
- As more and more people buy the public good, the average cost of the good drops.
- The price of the good drops, making the good available to more and more people.
- In this process, early buyers are refunded for the high price they paid in the beginning.
- In particular, because of the transfers from late buyers to early buyers, nobody has an incentive to wait with their purchase until prices drop.
All we need for this to work is for the website that coordinates this process to manage these transfer payments. Of course actually distributing money among many different bank accounts whenever a single purchase is made would incur way too much transaction costs. But the website could simply keep track of purchases and how revenue needs to be redistributed and allow customers to withdraw funds every once in a while. The transaction costs could be passed on to backers/buyers directly or could they could simply be financed from the interest the website earns from keeping the payments for some time.
It is also important to note that the infrastructure for pledging available on the website should still be used for sales, even after the product is finished. This way, if the current price for the game is still \$40, people who would be willing to pay \$20 for the product could submit this “bid” on the website. If enough people pledge \$20, the price of the product will actually drop and they will get a copy. The important thing is that people have an incentive to reveal the true price they are willing to pay! This is in contrast to a classical sales context, where customers have an incentive to understate their true valuation to get the company to lower their price.
The Benefits in Summary
The Average Cost Threshold Protocol is a practical mechanism for funding public goods that allow use exclusions. It is an implementation of the well-known fixed fee mechanism with average cost prices, and thus it enjoys many desirable properties:
- It is in everybody’s own best interest to pledge exactly what they are willing to pay. This is true even in hindsight!
- The protocol makes everybody better off. In particular, nobody is forced to pay anything.
- The costs of the project are guaranteed to be covered for the company.
- Among all possible mechanisms with these properties this one is optimal, that is, it creates the most value for society as a whole.
Beyond these theoretical merits, the practical protocol suggested above has a number of additional benefits:
- Prices to the public good are lowered continuously, in order to provide the widest possible audience with access to the public good as quickly as possible.
- At all times throughout the process, everybody has paid exactly the same price for access to the public good. So nobody has an incentive to wait with their purchase for prices to drop.
- In the sales-phase, it is in the interest of customers to bid what they would be willing to pay, even before prices drop. This allows the mechanism to lower prices more quickly, via optimal price targeting.
- Everybody benefits from getting more people to buy access. Even today, backers of crowd-funding projects often provide significant marketing services to their projects through word of mouth, long after fundraising has ended. Using this protocol, backers are not only personally rewarded for this engagement, but they also help to give more people access at lower prices.
Of course this is not the end of the story! There are a number of variants of this mechanism that are worth exploring.
Variations of the Protocol
There are a number of aspects of the basic version of the Average Cost Threshold Protocol presented above which can be improved further.
1) Most importantly, the public good provided by the protocol is still subject to use exclusions. We would really like to actually provide a pure public good that everybody has access to, no matter if they paid anything or not. But if we modified the mechanism so that people know the good is eventually going to be provided for free, the economic incentive to contribute something would disappear. Remember, this is the essence of the Myerson-Satterthwaite impossibility theorem!
Nonetheless, there are a number of ways the protocol could be modified to fund the creation of a pure public good without use exclusions. For example, we could set a “reserve price” of, say, \$5 dollars. If the price of the good falls below \$5, the good becomes a pure public good available to everyone for free. Now, of course, everyone who did pay \$5 has paid \$5 too much, which would destroy incentive compatibility in a strict sense. But as \$5 is a relatively small loss, backers who care about the project may very well be ready to accept this loss and gain the warm glow-effect of having made the public good available for everyone. Instead of fixing a common reserve price of \$5 for everyone, backers might also set their own individual reserve price when buying the product. (This of course would require the redistribution scheme to be adjusted.)
A completely different option would be to set a fixed “expiration date” of the use exclusions, for example, three years after the release of the finished product. Buyers would then purchase early access to the product, which is a common business model already today. The difference is that this early access would come with a guarantee that the product will become a pure public good eventually.
Of course such modifications would ruin some of the nice game theoretical properties of the mechanism. But these theorems hinge on the assumption that all backers are entirely rational anyway. And humans are not entirely rational, they are also benevolent and they tend to be tremendously enthusiastic about creative projects they like. So there is room enough for such small changes to work, even if they don’t fit into the rational framework.
2) Companies or creative individuals funding a project using the “vanilla” Average Cost Threshold Protocol as defined above enjoy the tremendous benefit of having their costs covered in advance by payments very similar to pre-purchases. They are not funded through equity and they have no liabilities, which means they have no investors that they need to satisfy through profits and they have no debt that they need to pay off. But that does not mean that all is well.
First of all, after the project is funded and the company received the payment to cover their costs, they are not going to receive any further payments, whatsoever. This means that they have no further economic incentives to make the project succeed. They may have incentives in terms of their creative ambition, their reputation as a company, their individual careers or simply their personal integrity. But the economic incentives to make the product shine, to market it well, to finish it on time and on budget or even to complete the project all - they are all gone. This is clearly not in the interest of anybody! Therefore it is a good idea to allow the company to make some profits in order to create the corresponding economic incentives.
Moreover, no matter how accurately the company projected the costs of the project at the outset, the actual development may run over budget. Projects often (always?) do. So despite the fact that the initial fundraising is expected to cover costs in advance, the company still faces financial risks. To make these financial risks worthwhile to the company, it stands to reason that the company is allowed to make some profit.
Fortunately it is straightforward to allow the company to make a profit and at the same time allow the public to enjoy decreasing prices. The rule is simple: Half of the payment a new buyer makes goes to the previous backers, the other half is profit for the company. An example. Initially, 20,000 backers paid \$50 each to raise \$1 million. Now, 10,000 additional buyers want access. According to the original protocol, everybody would have to pay \$33.33 now. But instead, we ask the newcomers to pay \$40. Half of that is the profit of the company, which amounts to \$200,000 in total. The other half goes towards refunding the original 20,000 backers so that everybody paid just \$40 in total. In this way, prices will decrease steadily with an increasing number of buyers. But still, the company stands to make an unlimited profit from creating a great product! This amounts to a reasonable compromise between the interests of the company and the social goal of giving access to as many people as possible.
The great thing about this variation is that it preserves many of the nice game-theoretic properties of the original mechanism. In particular, this modified mechanism is still incentive compatible and individually rational. It still covers costs by producing a budget surplus instead of a balanced budget. It is less efficient than before, because fewer people get access for the same amount of money. But still, as the number of buyers grows, the price goes to zero, enabling everybody to afford access if the public good becomes popular enough.
Of course, nobody says that revenues always have to be split 50-50 among the company and its backers. Any other ratio would do. The ratio could change over time. Or each backer could choose their own ratio (similar to what the Humble Bundle is doing), leading to a democratic vote on how revenues should be split. Also, this idea can be combined with the first variation presented above to create a protocol that produces both profits for the company and a public good without use exclusions, provided the good becomes popular enough. In this case the profits for the company are bounded and it is not entirely rational for buyers to reveal their true valuation, but still this promises to be an excellent compromise.
3) From a game theoretic perspective it is important (though not indispensable) that everybody pays the same price. However, from a practical perspective that may not be desirable. Some backers may want to be charged more than other backers. Maybe because they want to show how much they value the project. Maybe the company decides to offer rewards for backers who pay much. Most importantly, there is a real possibility that projects cannot be funded without backers who self-select to pay a very large premium on the average cost. The public interest in the project may not be broad enough to get the costs covered on an average cost pricing basis, but the interest may well be deep enough to cover costs if some people are allowed to pay more.
A special case is the money the company itself puts into the development. Companies and creators running crowd-funding projects often put a significant amount of personal wealth into their projects. Usually, these are funds that do not show up during the fundraising campaign. But an effective mechanism for funding public goods should explicitly incorporate a facility to account for this common practice.
Again there are several ways to allow backers to pay more than the average cost during the initial fundraising campaign. (Note that backers can always pledge as much as they want, but in the original protocol, they will never pay more than the average cost.) One way to accommodate this is via the variable reserve price mechanism mentioned above. Backers who want to pay a lot could simply set their personal reserve price to exactly the same amount as their pledge. Then, they could get charged the entire amount if the fundraising campaign is successful.
However, the above variation would also imply that these backers are not refunded anything. This may well be in the interest of very enthusiastic backers, but it would not fit the needs of the company who wants to recoup the large investment it made into the project in this way. Also there may be backers who are willing to make a very large payment, if the project can’t be funded otherwise, but would like to be refunded if the project turns out to be widely popular in the long run. To accommodate these interests, one could allow backers to specify that they want to be charged more during the fundraising campaign. Later on, the revenues earned from sales of the product could be used to refund backers in proportion to the payment they made during fundraising. This way large backers could eventually recoup their investment if the project is widely successful.
While it may generally not be rational for backers to make such large payments, the presence of this option does not change the fact that for the average backer the protocol remains incentive compatible and individually rational. As before, this variation can also be combined with the variations 1) and 2) mentioned above.
Conclusion
The Average Cost Threshold Protocol and its variations promise to yield an effective mechanism for the private funding of public goods. Even if this particular mechanism is not the ultimate answer, it shows that there is a lot of room out there for improving upon existing crowd-funding mechanisms in this regard. I hope that more people apply their creativity to invent new ways of making the private provision of public goods attractive. In a world where public goods make up an increasing share of the global economic output, such a mechanism could change the way we do business and interact with each other’s creative work.
]]>